Tekoälyteknologian nopea kehitys ravistelee käännösalaa ennennäkemättömällä tavalla. Kehitys on johtanut pohtimaan, kumpi toimii käännöstehtävissä paremmin ja tehokkaammin: neuroverkkokonekäännin (NMT) vai uudet suuret kielimallit (LLM)? Erikoistutkimuksemme antaa tietoa neuroverkkokääntimien ja suurten kielimallien toiminnasta.
Tutkimme kummankin teknologian vahvuuksia ja heikkouksia käyttämällä erilaisia arviointimittareita ja testidataa ja vertailemme niiden tuottamaa käännöslaatua, tehokkuutta ja käytännön soveltuvuutta. Tarkastelemalla eri teknologioita pyrimme selvittämään, mikä ratkaisu sopii parhaiten mihinkin käyttötapaukseen. Lue lisää löydöksistämme.
Pääkohdat
Yleisesti tässä tutkimuksessa hyvin koulutettu neuroverkkokäännin päihitti generatiivisen tekoälyn useimmissa avainmittareissa.
Metodologia
Acolad Labsin johtamassa tutkimuksessa hyödynnettiin edellisen vaiheen havaintoja ja käytettiin tosielämän sisältöjä, jotta voitiin varmistaa tutkimuksen merkityksellisyys käytännössä. Tutkimus koostui kahdesta osasta: Ensimmäinen osa keskittyi puhtaasti automaattiseen kääntämiseen. Neuroverkkokääntimen (NMT) ja suurten kielimallien (LLM) suoriutumista arvioitiin siis ilman jälkieditointia. Toisessa osassa prosessiin otettiin mukaan ihminen: koulutettu kieliasiantuntija tarkasti ja hioi koneiden luomat käännökset, jotta voitiin arvioida koneen ja tekoälyn yhteistyön tehokkuutta ja laatua. Ihmisten tekemistä tarkistuksista vastasi kolmannen osapuolen kielipalveluntarjoaja arvioinnin riippumattomuuden varmistamiseksi.
Vaiheessa oli mukana erilaisia kieliä: ranska, romania, ruotsi ja kiina. Arvioinnissa käytettiin kehotekirjastoa, jota oli kehitetty aiempien havaintojen perusteella, sekä paranneltuja termi- ja tyyliohjeita tekoälymalleille. Käytettyjä tekniikoita olivat muun muassa konekääntämisen sanaston puhdistustekniikat ja ristikkäiset kehotteiden abstrahointitekniikat. Tekoälykäännöksiä arvioitiin aiempaa laajemmin vertaillen useita neuroverkkokäännösjärjestelmiä ja suuria kielimalleja.
Kattavalla lähestymistavalla voitiin vertailla tekoälyn kyvykkyyttä yksityiskohtaisesti yritystason kieliratkaisuissa.
Osa 1
Automaattisten käännösten arviointi
Täysin automaattisesti tuotettujen käännösten analyysissa arvioitiin seuraavia järjestelmiä:
- esikoulutettu neuroverkkokonekäännin
- suuri kielimalli, jota käytettiin mukautetun tekoälyalusta-APIn kautta
- erilaisia suuria kielimalleja, joihin sisältyi muun muassa kattavasti parametreilla koulutettu malli ja suuren mittaluokan datan käsittelyyn erikoistunut malli: OpenAI:n ChatGPT-4 (Turbo), Mistral (Large), Llama 2 (70b) ja Acolad LLM.
Analyysissa käytettiin tosielämän sisältöä, joka sisälsi muotoilua, tyylimerkintöjä ja termiriippuvaisuuksia. Näin se edusti hyvin sisältöä, jota tyypillisesti lähetetään käännettäväksi. Sisältö esikäsiteltiin ja jäsenneltiin käännöstenhallintajärjestelmällämme tavalliseen tapaan. Automaattisia käännöksiä verrattiin käännöksiin, jotka oli tehnyt aihealueen tunteva kielialan ammattilainen.
Suuret kielimallit ohjattiin noudattamaan tiettyä terminologiaa ja tyyliä. Pyrimme myös parantamaan kielimallien tuotoksia muilla tekniikoilla, kuten antamalla malleille yhden tai useampia esimerkkejä halutusta lopputuloksesta. Kehotteiden osalta on tärkeää huomata, että eri palveluntarjoajien LLM:t edellyttävät erilaisia kehotestrategioita liittyen erityisesti sisällön tekniseen rakenteeseen.
NMT:n, LLM:ien ja ammattilaisten kääntämää sisältöä arvioitiin yleisillä toimialan mittareilla:
BLEU (Bilingual Evaluation Understudy): Yleisesti käytetty mittari, jolla verrataan, kuinka hyvin konekäännös vastaa laadukasta ihmiskäännöstä yhdenmukaisten sanajaksojen määrän perusteella.
chrF (Character Level F-score): Kun BLEU arvioi sanatason vastaavuuksia, chrF vertaa tuotosta ihanteelliseen käännökseen merkkitasolla.
COMET (Crosslingual Optimized Metric for Evaluation of Translation): Toisin kuin BLEU ja chrF, jotka perustuvat tilastolliseen vertailuun, COMET ennustaa neuroverkkojen avulla, miten ihminen arvioisi konekäännöksen.
PED (Post-Edit Distance): Tämä mittari mittaa, kuinka paljon vaivaa konekäännöksen jälkieditointi ihmiskäännöksen tasolle vaatii.
TER (Translation Edit Rate): PEDiä muistuttava TER mittaa, kuinka monta muokkausta tarvitaan, jotta saavutetaan täydellinen vastaavuus viitekäännöksen kanssa.
Englanti–ranska-kieliparissa Acoladin NMT päihitti kolme merkittävää suurta kielimallia – OpenAI:n ChatGPT-4:n (Turbo), Mistralin (Large) ja Llama 2:n (70b) – sekä oman kokeellisen suuren kielimallimme.
Se sai parhaat pisteet kolmesta tärkeästä arviointimittarista: BLEU, chrF ja COMET.
Hiljattain päivitetty ranskan kielen NMT-käännin sai myös parhaat PED- ja TER-tulokset (alhaisempi tulos parempi), jotka kertovat jälkieditoinnissa vaadittujen muokkausten määrästä.
Kuten edellä todettiin, suurten kielimallien tulos sijoittui lähelle 90. persentiiliä tai jopa sen yläpuolelle COMET-arvioinnissa, jota pidetään hyvänä kielellisen sujuvuuden mittarina. Tämän perusteella LLM:iä voidaan hyödyntää tulevaisuudessa kääntämisessä ja sisällöntuotannossa erityisesti ranskan kaltaisissa suurissa kielissä. Vahva COMET-tulos ei kuitenkaan takaa, että käännös vastaisi tarkkuuden, sanaston ja tyylin osalta asiakkaan odotuksia.

Englannista ruotsiin käännettäessä tulokset olivat samankaltaisia: NMT päihitti jälleen tärkeimmät LLM:t eri mittareilla mitattuna.

Englanti – yksinkertaistettu kiina -kieliparissa NMT sijoittui kärkisijalle kaikissa mittareissa – paitsi BLEU:ssa. Sanamerkkejä käyttävistä kielistä saadut tulokset vaihtelevat, mutta tokenisoinnin (menetelmä, jolla virkkeet jaetaan käsiteltäviin osiin, kuten sanoihin tai alisanoihin) parantuessa tulevat mallit tuottavat todennäköisesti entistä parempia tuloksia. Kannattaa myös huomata, että joidenkin asiantuntijoiden mielestä COMET on hyödyllisempi laatumittari.

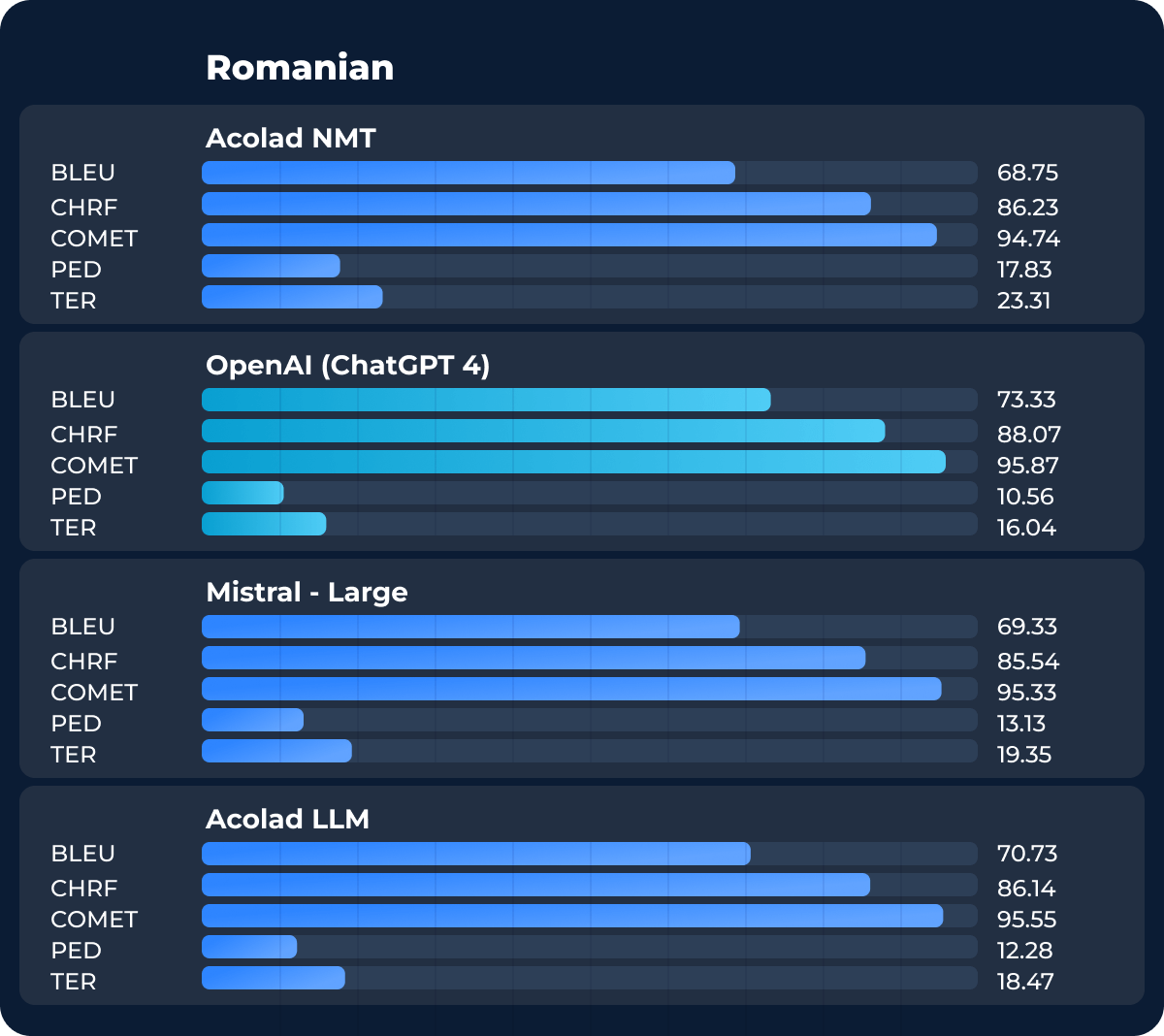
Viimeinen testikielemme oli romania, jossa OpenAI:n ChatGPT-4 päihitti täpärästi NMT-mallin kaikissa mittareissa. Tulokset olivat kuitenkin hyvin samansuuntaisia. Tiimimme hyödyntävät tulosta tämän konekäännösmallin jatkokehityksessä. Kaikkien NMT-järjestelmien tapaan kielimalleja on päivitettävä ja optimoitava ajan kuluessa.
Tässä vaiheessa on hyvä todeta, että LLM:t voivat tuottaa odottamattomia outouksia, vaikka laatumittarien tulokset olisivat hyviä. Palaamme tähän myöhemmin, kun selitämme tarkemmin näitä laatuanalyyseja.
Osa 2
Tulokset ammattimaisen kielentarkistuksen jälkeen
Täysin automaattisesti tuotettujen käännösten lisäksi halusimme arvioida tuloksia ammattimaisen kielentarkistuksen jälkeen (kutsumme lähestymistapaa nimellä Human-in-the-Loop, HITL), jotta saatoimme arvioida käännöslaatua mahdollisimman kattavasti. Näytteet toimitettiin arvioitaviksi kieliasiantuntijoille, joille asiakkaan tekstit olivat tuttuja. Puolueettomuuden varmistamiseksi arvioinnit tehtiin sokkotestinä. Kieliasiantuntijat arvioivat asiakkaalle toimitettua konekäännettyä ja jälkieditoitua sisältöä ja kirjasivat havaintonsa yksityiskohtaisiin tuloskortteihin (viisi kieltä kohti). Arvio sisälsi segmenttitason analyysin ja kielellisiä havaintoja.
HITL-arvioinneissa havaittiin, että vaikka LLM:t voivat tuottaa hyväksyttäviä käännöksiä, teksteissä oli merkittäviä virheitä, jotka ihmisen oli korjattava. NMT-järjestelmien käännökset vaativat vähemmän jälkieditointia: editointietäisyys (PED) ja käännösten muokkaustarve (TER) -tulokset olivat alhaisempia verrattuna suuriin kielimalleihin, kuten GPT-4:ään. HITL-arvioinnissa virheiden määrä vaihteli eri kielten välillä, ja esimerkiksi ruotsissa haasteita ja virheitä oli enemmän kuin vaikkapa ranskassa. Tämä osoittaa, että ihmisen tekemä tarkistus on erityisen tärkeä monimutkaisissa ja vähemmän käännetyissä kielissä.
Suurten kielimallien ja konekääntämisen tulevaisuus
Tulevaisuudessa suuret kielimallit kehittyvät varmasti entistä taitavimmiksi, mutta toistaiseksi koulutetut NMT-mallit vaikuttavat tuottavan johdonmukaisempia tuloksia, jotka on helpompi jälkieditoida vaaditulle laatutasolle. Tämä pätee erityisesti tosielämän sisältöön, jota käsitellään perinteisissä käännöksenhallintajärjestelmien työnkuluissa.
On myös tärkeää huomata, että toimialakohtaisella sisällöllä ja terminologialla koulutetut NMT-mallit eivät kärsi tietyistä teknisistä haasteista ja omituisuuksista, jotka vaivaavat generatiivista tekoälyä.
NMT toimii ajan myötä ennustettavammin kielissä, joita se on viritetty kääntämään. Vertasimme aiemmin myös geneerisen NMT:n tuotosta LLM:n tuotokseen, ja vaikka laatu oli heikompi (pidempi editointietäisyys jne.), tulosten ennakoituvuus oli hyvä. Suurten kielimallien osalta laatu heikkenee nopeasti, erityisesti kun lähdekieli on muu kuin englanti ja yleisesti kielissä, joissa materiaalia on saatavilla vähemmän. Tuotetun sisällön laatu voi vaihdella merkittävästi.
Yksi esimerkki liittyy tekoälyn hallusinointiin – erityisesti pienemmissä kielissä – joka voi tehdä käännöksestä jopa hyödyttömän. Tämä näkyi erityisesti teknisen sisällön, kuten URL-osoitteiden, asiakas- tai alakohtaisen terminologian ja lyhyiden virkkeiden virheellisenä käsittelynä. LLM:t eivät siis vielä tuota yhtä luotettavia tuloksia, kun käsitellään suuria määriä sisältöä.
Yleisesti Acoladin tulokset asiantuntijan tekemän tarkistuksen jälkeen osoittivat, että vaikka suurten kielimallien tuottamat käännökset saivat verrattain korkeat pisteet, monimutkainen sisältö, joka sisälsi esimerkiksi rakenteellisia elementtejä ja muotoilua, aiheutti ongelmia.
Lisäksi verrattain monimutkaisten kehotteiden hallitseminen eri kielissä ja malleissa nostaa suurten kielimallien laajan hyödyntämisen kustannuksia, vaikka raa’an käsittelyn kustannukset ovatkin laskeneet.
Jos siis tarkoitus on kääntää automaattisesti suuria määriä sisältöjä ilman ihmisen työpanosta, laadukas konekäännösratkaisu on todennäköisesti parempi ratkaisu – ainakin toistaiseksi.
Kuten aiemmin totesimme, myös ihmisen osallistuessa käännöksen editointiin konekäännös voi olla kustannustehokkaampi vaihtoehto generatiiviseen tekoälyyn verrattuna, kun kehotteiden hiomiseen ei tarvitse käyttää aikaa. NMT:n editointietäisyys (PED) ja käännösten muokkaustarve (TER) ovat myös pienemmät, eli raakakäännösten korjaaminen vaatii vähemmän työtä kuin suurten kielimallien käännösten.
Näistä tuloksista huolimatta on selvää, että suuriin kielimalleihin perustuvalla generatiivisella tekoälyllä on tulevaisuudessa suuri rooli automaattisessa kääntämisessä – erityisesti mallien kehittyessä entisestään. Sille voidaan löytää mielenkiintoisia käyttötapauksia, kuten konekäännöksen tyylillinen hiominen. Löydösten perusteella suurilla kielimalleilla voi olla merkittävä rooli laatuarvioinneissa, ja mallien kykyjä voidaan hyödyntää myös esimerkiksi automaattisessa jälkieditoinnissa.
LLM:t tarjoavat mielenkiintoisia mahdollisuuksia liittyen monimerkityksellisyyksien, idiomien, kulttuuristen viittausten ja jopa huumorin käsittelyyn. Juuri tällaisten elementtien kanssa jotkin konekäännösmallit ovat olleet vaikeuksissa liittyen datasarjoihin, joiden pohjalta mallit on rakennettu.
NMT vai LLM: oikean valinnan tekeminen
Neuroverkkokääntimen (NMT) tai suurten kielimallien (LLM) valintaan vaikuttavat tarkat käännöstarpeet ja konteksti, jossa teknologiaa hyödynnetään. Jos tarkoituksena on kääntää erikoistunutta sisältöä nopeasti ja tarkasti, NMT on selvästi parempi vaihtoehto. Se on suunniteltu erityisesti käännöstehtäviä varten ja päihittää yleensä LLM:t tarkkuudessa. Toisaalta NMT:n kouluttaminen voi vaatia merkittävää investointia, ja joskus lopputuloksen luonnollisuudessa voi olla toivomisen varaa.
Jos projekti edellyttää luontevaa, epämuodollista kieltä – erityisesti englanniksi – ja tuotosten hiomiseen voidaan käyttää aikaa, LLM:t voivat soveltua tarkoitukseen paremmin. Ne toimivat hitaammin kuin NMT ja vaativat enemmän resursseja, mutta niiden tuotoksia voidaan parantaa merkittävästi kehotteiden suunnittelutekniikoilla. Kannattaa myös muistaa suurten kielimallien taipumus tuottaa epätasaisia tuloksia ja mahdollisesti virheitä, kuten hallusinointia tai epäolennaisia lisäyksiä.
Yhteenvetona NMT on oikea valinta, kun tarvitaan nopeasti tarkkoja käännöksiä ja kehitystyöhön on käytettävissä riittävä budjetti. LLM on puolestaan hyvä vaihtoehto, jos projektissa on mahdollista kehittää syötettä ja tavoitteena on luonteva, epämuodollinen kieli. Huomioi kuitenkin tällöin korjausten mahdollinen tarve.
![]() 5. kesäkuuta 2024
5. kesäkuuta 2024 ![]() Käännökset
Käännökset

Tietoa Acolad Labsista
Acolad Labs on Acoladin osasto, joka kehittää räätälöityjä ratkaisuja Acoladin teknologiaportfolioon. Tiimi on muodostettu monimuotoisesta joukosta teknisiä asiantuntijoita ja kokeneita ohjelmistosuunnittelijoita. Asiantunteva tiimi varmistaa, että uudet innovaatiot sekä vastaavat asiakkaiden kehittyviä tarpeita että täydentävät olemassa olevaa tuotesalkkua.