The field of translation is experiencing unprecedented transformation due to the rapid advances in Artificial Intelligence technology. This evolution has sparked a key question: does Neural Machine Translation (NMT) or the newer Large Language Models (LLMs) offer superior performance and efficiency for translation tasks? Our exclusive research provides a direct insight into the performance of NMT and LLMs.
Using a variety of evaluation metrics and test datasets, we explore the strengths and weaknesses of each technology and their impact on translation quality, efficiency, and application. By examining these technologies, we aim to uncover which solution is most promising for specific use cases. Join us to discover more.
Key highlights
Overall, this research showed that a well-trained NMT model outperforms generative AI in most key metrics.
Methodology
This research, led by Acolad Labs and building on insights from a previous phase, involved real-world content to ensure practical relevance. The study consists of two main components: The first component focuses on purely automated translation, where the performance of Neural Machine Translation (NMT) and Large Language Models (LLMs) are evaluated without any human post-editing. The second component involves a "human in the loop" approach, where professional linguists review and refine the machine-generated translations, assessing the combined efficiency and quality of human-AI collaboration. Human reviews were conducted by a third-party Language Service Provider to ensure an independent evaluation.
This phase included additional mixed-tier languages, specifically French, Romanian, Swedish, and Chinese. An improved prompt library, based on previous learnings, was utilized along with enhanced terminology and style instructions for AI models. This included glossary cleaning techniques from machine translation and cross-model prompt abstraction techniques. A broader range of comparisons across the AI translation landscape was introduced, evaluating multiple neural machine translation systems and large language models.
This comprehensive approach allowed for a detailed comparison of AI capabilities in enterprise-level language solutions.
Part 1
Automated Translation Performance Evaluation
For the fully automated output analysis, the systems evaluated included:
- A pre-trained neural machine translation engine
- A large language model accessed via a custom AI platform API
- Various large language models, including one trained with extensive parameters and another focused on large-scale data processing: OpenAI’s ChatGPT-4 (Turbo), Mistral (Large), Llama 2 (70b), and Acolad LLM.
The analysis used real-world content including formatting, stylized with inline tagging ,and terminology dependencies: a good representation of the type of content often sent for translation. This content was pre-processed and parsed through our translation management system in the usual way, and comparisons from the automated outputs were performed against professionally translated content by linguists familiar with the domain of content under test.
The LLMs were prompted to constrain their output to specific terminology and style, while we also employed other techniques, like one-shot/few-shot prompt abstractions to try and improve the LLM output. One important note is that LLMs from different providers required different prompting strategies, particularly as it related to the technical structure of the content.
The outputs from NMT, LLMs and professionally translated content were then run through a range of industry metrics:
BLEU (Bilingual Evaluation Understudy): A widely used metric that compares how close a machine translation is to a high-quality human translation that focuses on how many sequences of words match.
chrF (Character Level F-score): While BLEU evaluates word-level matches, chrF looks at similarity of the output to an ideal translation on a character-level.
COMET (Crosslingual Optimized Metric for Evaluation of Translation): Unlike BLEU or chrF, which rely on statistical comparisons, COMET uses the power of neural networks to predict how humans would rate a machine translation.
PED (Post-Edit Distance): This metric measures the effort required to transform a machine translation output into a high-quality human translation.
TER (Translation Edit Rate): While similar to PED, TER focuses on the number of edits needed to achieve a perfect match with a reference translation.
For the English-to-French language pair, Acolad NMT outperformed three major AI LLMs: OpenAI’s ChatGPT-4 (Turbo), Mistral (Large), Llama 2 (70b), and our own experimental LLM.
It scored best in three major quality evaluation metrics BLEU, chrF and COMET.
The recently updated French NMT engine also performed best in the PED and TER metrics (lower is better), which measure how many edits a post-editor must make to correct the text.
As noted, the output from LLMs performed well on COMET, considered to be a good measure of the linguistic fluency of a result, with scores near or above the 90th percentile. This indicates that LLMs have a future in translation and content generation, and particularly so with well-resourced languages like French. The strong COMET scores, however, may not align with client expectations for accuracy, glossary, and style expectations.

In English to Swedish, the results were similar, with NMT again outperforming major LLM models across the board.

For the English-Chinese (Simplified) language pair, the NMT engine performed best in all metrics - except for BLEU. Logographic languages, such as Chinese, continue to present mixed results, but with improving tokenization (the method by which sentences are broken down into more manageable sizes, such as words or sub-words), upcoming models will likely show improved results. It’s also worth noting that some experts argue COMET is a more useful quality metric.

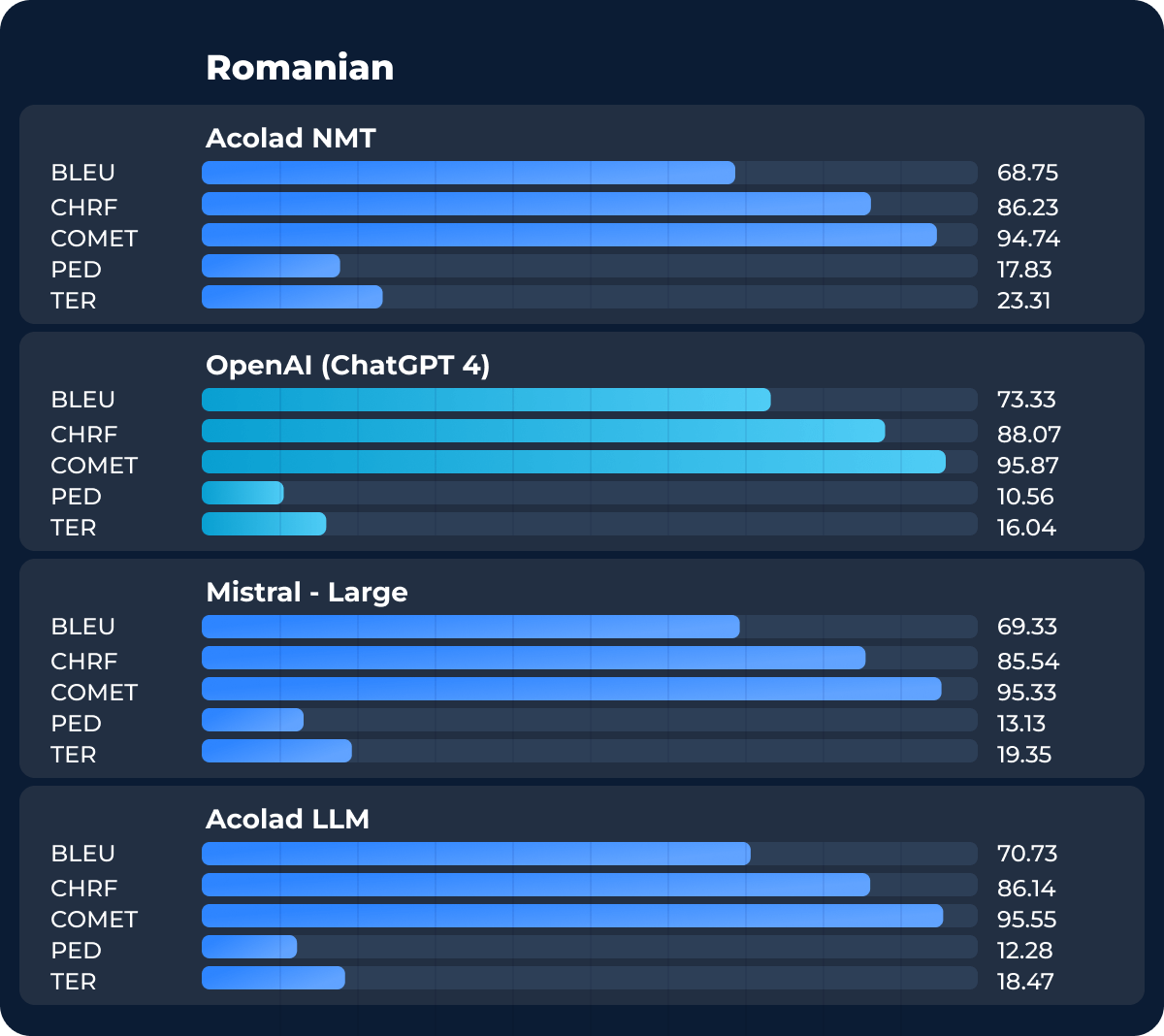
In our final test language, Romanian, OpenAI’s ChatGPT-4 slightly outperformed the NMT model in all metrics, though the results were quite similar. Our teams will be using this result to further iterate and improve this machine translation model. As with all NMT systems, the language models must be updated and optimized over time.
However, it’s worth noting that LLMs can throw up some other unexpected quirks even when scoring higher with quality metrics. We’ll look at that later on, after we explain more about these quality analyses.
Part 2
Human-in-the-Loop, the Professional Linguistic Review
In addition to evaluating fully automated translation outputs, we wanted to incorporate a Human-in-the-Loop (HITL) assessment to ensure a comprehensive evaluation of translation quality. All samples were provided to client-trained linguists and presented as a blind test to ensure unbiased evaluation. Linguists re-evaluated the MTPE’d (Machine Translation Post-Edited) content delivered to the client and provided detailed scorecard results (five per language), with segment-level analysis and linguist commentary for further inspection.
The HITL assessments revealed that while LLMs can produce acceptable translations, there were still significant errors that required human intervention. NMT systems showed better performance in reducing post-editing efforts, with lower Post-Edit Distance (PED) and Translation Edit Rate (TER) scores compared to LLMs like GPT-4. The HITL assessment highlighted varying error rates across different languages, with some languages, such as Swedish, presenting more challenges and higher error rates compared to others like French. This indicates that human review is particularly crucial for complex or less frequently translated languages.
What This Means for the Future of LLMs and Machine Translation
As we look to a future where LLMs become increasingly sophisticated, it seems that for now, tuned NMT models produce more consistent results, that are easier to post-edit to high quality, particularly with real-world content processed in classic translation management system workflows.
It’s also important to note that highly trained NMT models (using specific domain content and terminology) aren’t subject to some of the technical challenges and quirks that persist when using generative AI.
NMT offers higher predictability, especially over time, and across tuned languages. We also previously compared generic NMT output to LLMs output, and while the quality is lower (increased post edit distances etc.), the predictability in the output is consistent. With LLMs, quality tapers off quickly and, notably so with non-English languages as a source, and for less well-resourced languages in general. Content output can vary quite materially over time.
One example relates to AI hallucinations – especially in lower-resourced languages – which can affect output to the point where the translation is simply not useful. This was seen in incorrect handling of technical content such as URLs, client or domain specific terminology and short sentences, meaning LLMs don’t yet produce such reliable results when processing content in large batches, or at scale.
Generally, Acolad results combined with expert human review showed that while the LLM output did score relatively highly, it struggled with more complex content with structural elements, like formatting, and inline tagging.
Further, with the requirement to manage relatively complex prompts across languages and models, the broader application of LLM technology in translation workflows will add to the total cost of translation, even though raw processing costs are dropping.
Effectively, if you require automated translations for large amounts of content without human input or post-editing, it’s likely better to rely on a quality, proven machine translation solution - for now.
As we already noted, even when employing a human-in-the-loop to edit the automatic translation output, it can still be more cost-effective to use machine translation over generative AI, simply because of the time saved from iterating over prompts to refine the output of the LLM. Additionally, NMT has a lower Post-Edit Distance (PED) and Translation Edit Rate (TER), meaning it requires less work to correct compared to starting with LLM.
Despite these results, it’s clear that Generative AI LLMs will still have a large role to play in automating translations - especially as the models are refined. It has exciting potential applications in its use to stylistically rewrite MT output, for example. There is strong evidence that LLMs could play a pivotal role in quality evaluation, and this may support capabilities in translation such as self-reflecting post-editing.
They clearly display exciting possibilities when dealing with ambiguities, idioms, cultural references, and even humor that some MT models have traditionally struggled with given the contained data sets used to build their models.
NMT VS LLM: How to make the right choice?
Choosing between Neural Machine Translation (NMT) and Large Language Models (LLMs) depends on your specific translation needs and the context in which the technology will be employed. If your priority is speed and accuracy for specialized content, NMT is the superior choice. It is specifically tailored for translation tasks and typically outperforms LLMs in accuracy, although it may require significant investment in training and occasionally result in less natural translations.
On the other hand, if your project demands more natural, conversational language -particularly in English - and you can dedicate time to fine-tuning the outputs, LLMs might be more suitable. They are notably slower and resource-hungry compared to NMT, but their outputs can be improved significantly with techniques in prompt engineering. However, be mindful of their tendency to produce inconsistent results and potential errors, such as hallucinations or irrelevant additions.
In summary, you should opt for NMT if quick delivery of highly accurate translations is critical and budget permits investment in its development. Choose LLMs if the project allows for more developmental input and benefits from the production of fluent, conversational language, keeping in mind the need for potential corrections.
![]() June 5, 2024
June 5, 2024 ![]() Translation
Translation

About Acolad Labs
Acolad Labs is a specialized division within Acolad dedicated to developing customized solutions to enhance Acolad’s existing technology stack. Comprising a diverse team of tech experts and seasoned software designers, this elite team ensures each innovation not only meets the evolving needs of customers but also complements the established product portfolio.