Le domaine de la traduction connaît une transformation sans précédent, en raison des progrès rapides en matière d’intelligence artificielle. Cette évolution a soulevé une question fondamentale : est-ce que la traduction automatique neuronale (TAN ou Neural Machine Translation) ou les grands modèles de langage (GML ou Large Language Models) plus récents offrent des performances et une efficacité optimales pour les tâches de traduction? Nos travaux de recherche exclusifs donnent un aperçu direct des performances de la TAN et des GML.
À l’aide d’une variété de mesures d’évaluation et d’ensembles de données d’essais, nous analysons les forces et les faiblesses de chaque technologie et leur impact sur la qualité de la traduction, l’efficacité et l’application. En analysant ces technologies, nous cherchons à découvrir la solution la plus prometteuse pour des cas d’utilisation spécifiques. Rejoignez-nous pour en savoir plus.
Points à retenir
De manière générale, les travaux de recherche ont démontré qu’un modèle de TAN bien entraîné surpasse l’IA générative dans la plupart des aspects clés.
Méthodologie
Ces recherches, menées par Acolad Labs et basées sur les données d’une étude précédente, ont fait appel à du contenu de la vie réelle pour garantir la pertinence pratique. L’étude consiste en deux composantes principales : La première composante se concentre sur la traduction purement automatique, dans laquelle les performances de la traduction automatique neuronale (TAN) et les grands modèles de langage (GML) sont évalués sans aucune postédition humaine. La seconde composante implique une approche avec intervention humaine, dans laquelle des linguistes professionnels révisent et peaufinent les traductions générées automatiquement, évaluant l’efficacité et la qualité combinées de la collaboration humain-IA. Les révisions humaines ont été effectuées par un fournisseur de services linguistiques tiers afin de garantir une évaluation indépendante.
Cette phase comprenait des langues additionnelles diverses, en particulier le français, le roumain, le suédois et le chinois. Une bibliothèque améliorée de requêtes, basée sur des enseignements antérieurs, a été utilisée conjointement avec une terminologie et des instructions stylistiques optimisées pour les modèles IA. Étaient incluses des méthodes de nettoyage de glossaire issues de techniques d’abstraction de requêtes selon un modèle croisé et de traduction automatique. Un éventail plus large de comparaisons dans le cadre de la traduction assistée par l’IA a été intégré, évaluant ainsi les multiples systèmes de traduction automatique neuronale et grands modèles de langage.
Cette approche complète a permis d’obtenir une comparaison détaillée des capacités de l’IA dans les solutions linguistiques à l’échelle de l’entreprise.
Partie 1
Évaluation des performances de la traduction automatique
Pour l’analyse du résultat entièrement automatisé, les systèmes évalués comprenaient :
- Un moteur de traduction automatique neuronale pré-entraîné
- Un grand modèle de langage accessible via une plateforme API d’IA personnalisée
- Des grands modèles de langage variés, dont l’un a été entraîné avec des paramètres approfondis, et un autre axé sur le traitement de données à large échelle : ChatGPT-4 d’OpenAI (Turbo), Mistral (Large), Llama 2 (70b), et GML Acolad.
L’analyse a été réalisée avec du contenu de la vie réelle, notamment le formatage avec du balisage en ligne, et les dépendances terminologiques : un type de contenu représentatif de ce que l’on reçoit fréquemment en traduction. Ce contenu a été pré-traité et analysé normalement grâce à notre système de gestion des traductions, et les résultats obtenus automatiquement ont été comparés au contenu traduit par des linguistes professionnels, familiers avec le domaine du contenu à l’étude.
Les GML ont été entraînés pour restreindre leur résultat à une terminologie et un style spécifiques, alors que nous avons également employé d’autres méthodes telles que les abstractions des requêtes d’apprentissage avec un exemple ou peu d’exemples pour tenter d’améliorer le résultat produit par les GML. Il est important de noter que les GML de différents fournisseurs exigeaient des stratégies d’invites différentes, particulièrement en ce qui concerne la structure technique du contenu.
Les résultats de la TAN, des GML et du contenu traduit par des professionnels ont ensuite été soumis à une série de mesures du secteur :
BLEU (Bilingual Evaluation Understudy) : une mesure très utilisée qui compare à quel point une traduction automatique se rapproche d’une traduction humaine de grande qualité, et qui accorde de l’importance au nombre de correspondances entre les séquences de mots.
chrF (Character Level F-score) : alors que BLEU évalue les correspondances au niveau des mots, chrF étudie la similarité du résultat par rapport à une traduction idéale au niveau des caractères.
COMET (Crosslingual Optimized Metric for Evaluation of Translation) : contrairement aux modèles BLEU et chrF, qui se basent sur des comparaisons statistiques, COMET utilise la puissance des réseaux de neurones pour prédire comment les humains évalueraient une traduction machine.
Distance de postédition (post-edit distance) : cette métrique mesure l’effort nécessaire pour transformer un résultat de traduction automatique en une traduction humaine de grande qualité.
Taux de modification de la traduction (translation edit rate) : similaire au score de distance de postédition, le taux de modification de la traduction se concentre sur le nombre de modifications nécessaires pour atteindre une correspondance parfaite avec une traduction de référence.
Pour la combinaison anglais-français, la TAN Acolad a surpassé trois grands GML d’IA : ChatGPT-4 d’OpenAI (Turbo), Mistral (Large), Llama 2 (70b), et notre GML expérimental.
Les meilleurs résultats ont été obtenus dans les trois principales mesures d’évaluation de la qualité BLEU, chrF et COMET.
Le moteur français de TAN, récemment mis à jour, a également obtenu les meilleurs résultats de distance de postédition et de taux de modification de la traduction (le score le plus faible est préférable), qui mesurent le nombre de modifications à effectuer par la personne responsable de la postédition.
Comme indiqué, le résultat des GML était satisfaisant sur COMET, considéré comme une bonne mesure de la fluidité linguistique d’un résultat, avec des scores se rapprochant du 90e percentile ou au-delà. Cela démontre que les GML ont un avenir dans la traduction et la génération de contenu, en particulier pour des langues bien documentées comme le français. Il se peut, en revanche, que les scores COMET élevés ne soient pas alignés avec les attentes du client en matière de précision, de glossaire et de style.

Dans la combinaison anglais-suédois, les résultats étaient similaires, la TAN surpassant à nouveau les principaux modèles GML à tous les niveaux.

Pour la combinaison anglais-chinois (simplifié), le moteur TAN obtient les meilleurs résultats dans toutes les mesures, à l’exception de BLEU. Les langues logographiques, comme le chinois, continuent de présenter des résultats mitigés, mais avec l’amélioration de la tokenisation (la méthode selon laquelle les phrases sont décomposées dans des tailles plus gérables, telles que des mots ou des sous-mots), les modèles à venir afficheront certainement de meilleurs résultats. Il convient également de noter que certains spécialistes soutiennent que COMET est une mesure de qualité plus utile.

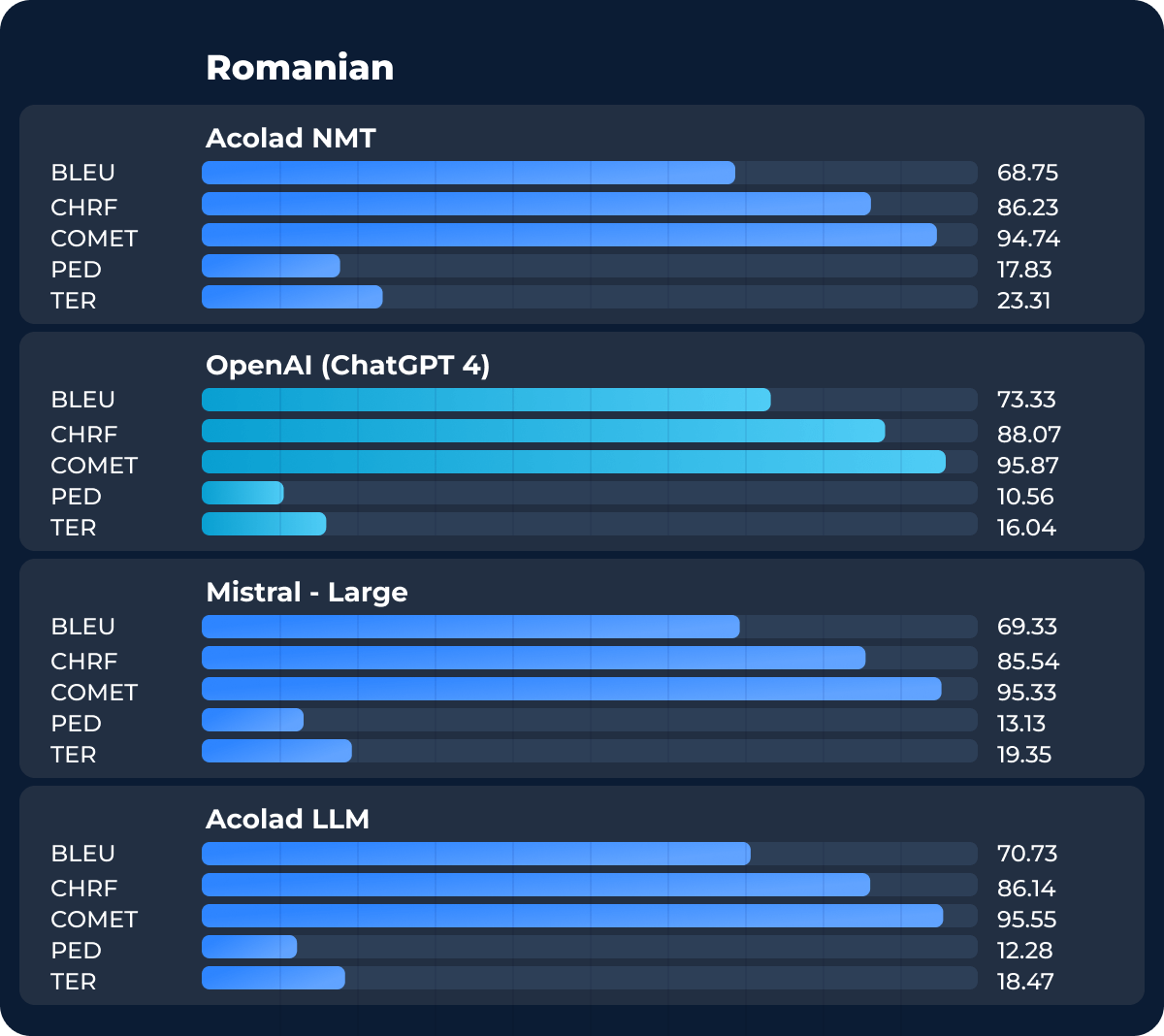
Pour notre dernière langue de test, le roumain, ChatGPT-4 d’OpenAI a légèrement surpassé le modèle TAN dans toutes les métriques, bien que les résultats soient assez similaires. Nos équipes utiliseront ce résultat pour réitérer et améliorer ce modèle de traduction automatique. Comme pour tous les systèmes de TAN, les modèles linguistiques doivent être mis à jour et optimisés au fil du temps.
Cependant, il convient de noter que les GML peuvent générer d’autres variations inattendues même lorsque les mesures de qualité obtiennent des scores plus élevés. Nous y reviendrons après avoir expliqué plus en détail ces analyses de la qualité.
Partie 2
Traduction avec intervention humaine – la révision linguistique professionnelle
En plus d’évaluer les résultats de la traduction entièrement automatisée, nous voulions intégrer une intervention humaine pour assurer une évaluation complète de la qualité de la traduction. Tous les échantillons ont été fournis à des linguistes formés par le client et présentés à l’aveugle pour assurer une évaluation impartiale. Les linguistes ont réévalué le contenu postédité livré au client et fourni des résultats détaillés de la fiche d’évaluation (cinq par langue), avec une analyse par segment et des commentaires linguistiques pour une vérification plus approfondie.
Les évaluations ont révélé que même si les GML sont en mesure de produire des traductions acceptables, il y a encore des erreurs importantes qui nécessitent une intervention humaine. Les systèmes de TAN ont produit de meilleurs résultats pour faciliter la postédition, avec des scores de distance de postédition et un taux de modification de la traduction inférieurs à ceux des GML comme GPT-4. L’évaluation humaine a mis en évidence des taux d’erreur variables dans différentes langues, certaines langues, comme le suédois, présentant plus de défis et des taux d’erreur plus élevés que d’autres, comme le français. Cela indique que la révision humaine est particulièrement nécessaire pour les langues complexes ou moins souvent traduites.
Qu’en est-il de l’avenir des GML et de la traduction automatique?
Alors que nous envisageons un avenir dans lequel les GML deviendraient de plus en plus sophistiqués, il semble qu’à l’heure actuelle, les modèles de TAN adaptés fournissent des résultats plus cohérents, plus faciles à postéditer pour obtenir une qualité élevée, en particulier lorsqu’il s’agit de contenu de la vie réelle traité dans des flux de travaux classiques de système de gestion de traduction.
Il est également important de souligner que les modèles de TAN hautement entraînés (recourant à un contenu et à une terminologie spécifiques à un domaine) ne sont pas soumis aux difficultés techniques et bizarreries qui persistent avec l’IA générative.
La TAN offre une plus grande prévisibilité, en particulier au fil du temps, et pour les langues adaptées. Nous avions également comparé les résultats de la TAN générique et des GML, et alors que la qualité est inférieure (score distance de postédition accru, etc.), la prévisibilité du résultat est constante. Avec les GML, la qualité diminue rapidement, notamment avec des langues autres que l’anglais comme source, et avec des langues moins bien documentées de manière générale. La qualité du contenu peut varier considérablement au fil du temps.
Un exemple concerne les hallucinations de l’IA – en particulier pour les langues moins documentées – qui peuvent affecter le résultat au point d’obtenir une traduction inexploitable. Ce cas a été observé lors de la mauvaise gestion de contenu technique tel que des URL, de la terminologie spécifique à un client ou au domaine et des courtes phrases. Cela démontre que les GML ne produisent pas encore de résultats aussi fiables lorsque le contenu est traité dans de gros volumes, ou à grande échelle.
Dans l’ensemble, les résultats d’Acolad associés à la révision par un spécialiste ont révélé que bien que l’évaluation des résultats produits par les GML est relativement élevée, le contenu plus complexe, compte tenu d’éléments structurels comme le formatage ou le balisage en ligne, présente un plus grand défi.
Par ailleurs, pour répondre à l’exigence de traiter des requêtes relativement complexes dans plusieurs langues et modèles, l’application plus étendue de la technologie de GML dans les flux de traduction ajoutera au coût total de la traduction, même si les coûts de traitement brut sont en baisse.
Effectivement, si vous avez besoin de traduire automatiquement des volumes importants de contenu sans intervention humaine ou en postédition, il est préférable, pour l’instant, d’opter pour une solution de traduction automatique de qualité éprouvée.
Comme évoqué précédemment, même en faisant appel à un humain pour éditer le résultat de la traduction automatique, il peut être plus coûteux d’utiliser la traduction automatique par rapport à l’IA générative, simplement grâce au temps économisé par la répétition des requêtes pour peaufiner le résultat du GML. En outre, la TAN affiche des scores de distance de postédition et un taux de modification de la traduction inférieurs, elle nécessite donc moins de travail de correction comparativement aux résultats de GML.
Malgré ces résultats, il est clair que les GML de l’IA générative auront toujours un rôle important à jouer dans l’automatisation des traductions, en particulier grâce à la précision des modèles. Ils présentent un potentiel intéressant dans leur application, par exemple pour la réécriture stylistique du résultat de TA. Des éléments extrêmement probants indiquent que les GML pourraient jouer un rôle décisif dans l’évaluation de la qualité, ce qui pourrait soutenir les capacités en traduction telles que la postédition auto-réflective.
Ils affichent clairement des possibilités intéressantes dans le traitement des ambiguïtés, expressions idiomatiques, références culturelles, et même des tournures humoristiques que certains modèles de TA ont du mal à traiter, compte tenu des ensembles de données utilisés pour façonner leurs modèles.
TAN VS GML : comment faire le bon choix?
Le choix entre traduction machine neuronale (TAN) et grands modèles de langage (GML) dépend de vos besoins spécifiques en traduction et du contexte dans lequel sera employée la technologie. Si votre priorité réside dans la vitesse et la précision pour du contenu spécialisé, la TAN est l’option à privilégier. Cette dernière est spécialement conçue pour les tâches de traduction et surpasse habituellement les GML en matière de précision, même si cette option peut nécessiter un investissement plus important dans la formation et peut produire occasionnellement des traductions moins naturelles.
D’un autre côté, si votre projet requiert un langage plus familier et naturel, en particulier en anglais, et que vous avez le temps de peaufiner le résultat, les GML pourraient être plus adaptés. Ils sont nettement plus lents et consommateurs de ressources par rapport à la TAN, mais leurs résultats peuvent être considérablement améliorés grâce à des techniques d’ingénierie de requêtes. Cependant, gardez à l’esprit qu’ils ont tendance à produire des résultats incohérents et de potentielles erreurs, comme des hallucinations ou des ajouts non pertinents.
En résumé, optez pour la TAN si la livraison rapide de traductions d’une grande précision est primordiale, et que votre budget vous permet d’investir dans son développement. Choisissez les GML si le projet permet un résultat plus orienté vers le développement, et tire profit d’un langage fluide et naturel, en tenant compte des éventuelles corrections à apporter.
![]() 5 juin 2024
5 juin 2024 ![]() Traduction
Traduction

À propos d’Acolad Labs
Acolad Labs est une division spécialisée au sein d’Acolad qui se consacre à l’élaboration de solutions sur mesure pour améliorer l’infrastructure technologique existante d’Acolad. Composée d’un vaste réseau de spécialistes techniques et de concepteurs de logiciels chevronnés, cette équipe d’élite veille à ce que chaque innovation répondent aux besoins changeants des clients et vienne compléter le portefeuille de produits établi.